For Careers
Learn MoreUsing streaming technologies with Kafka +Spark + Cassandra to effectively gain insights on data.

Internet Protocol Published. Reference: Documents that changed the world ISBN 978–0–7537–3386–8
A tremendous stream of data is consumed and created by applications these days. These data include application logs, event transaction logs (errors, warnings), batch job data, IoT sensor data, social media, other external systems data and much many more. All this data flow can be piped through the data pipelines or stages that can give insights and provide tremendous benefits to the organization. As it was mentioned recently in an article in the Economist, “The world’s most valuable resource is no longer oil, but data”.
This article covers one practical approach in using the data streams following the Lambda Architecture.
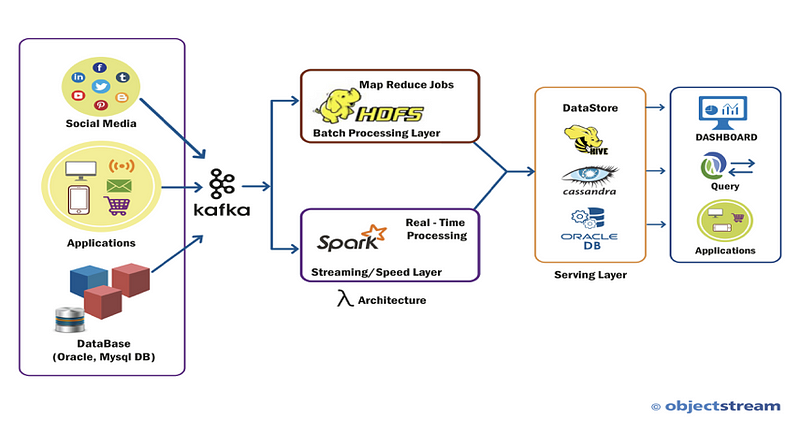
Kafka-Spark-Cassandra Architecture
Technologies like Kafka, Spark, and Cassandra are highly resilient, low-latency, fault-tolerant systems that have proven in high-throughput scenarios for scaling to petabytes of processing. Kafka is primarily a distributed message transport system. Hadoop is used for batch processing systems. This article will provide detail on real-time or near real-time processing using Spark streaming.
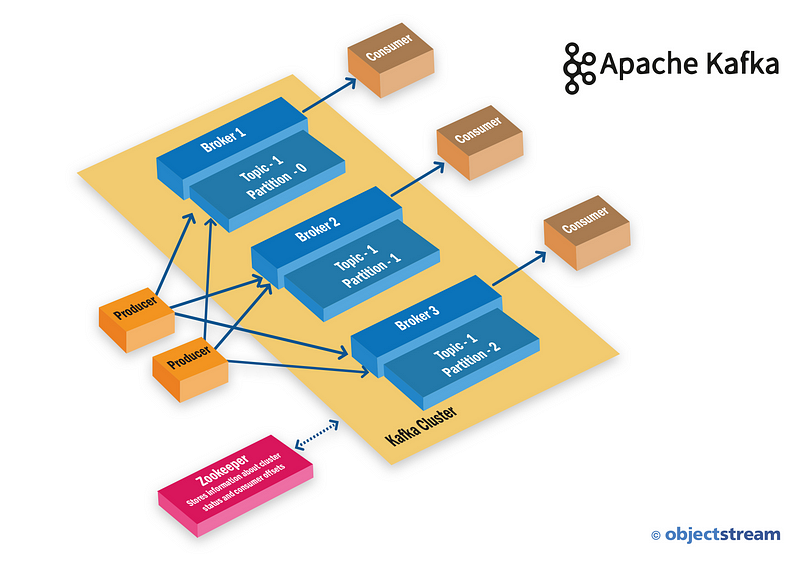
Kafka Internal Architecture
Apache Spark provides abstractions that are very useful to the developer proficient in Python, Java, Scala or R. It provides easy-to-use API for SQL, Streaming, Machine Learning Library and Graph (network) related operations.
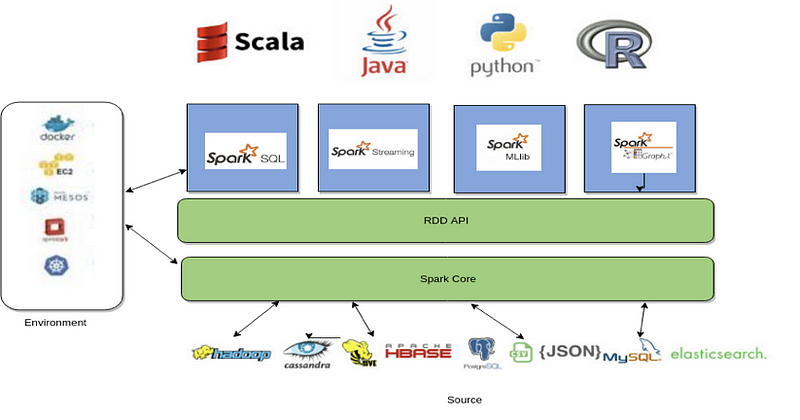
Spark high-level Architecture
Implementation of the above architecture: This code example shows how Kafka messaging is used. In order to run the following steps, you have to install, Kafka, Spark, and Cassandra. If you want to know the details on installation, refer to this GitHub page.
Step-1. Run the Zookeeper before starting the Kafka Server
bin/zookeeper-server-start.sh config/zookeeper.properties

Zookeeper Start
Step-2. Start the Kafka Server
bin/kafka-server-start.sh config/server.properties

Kafka-Server Start
Step-3. Create a Topic for Producers to publish, in our case “item_sales”
bin/kafka-topics.sh — create — bootstrap-server localhost:9092 — replication-factor 1 — partitions 1 — topic item_sales

Create the Topic “item-sales”
The replication factor is nothing but a backup used for data loss protection. The example in this article uses the localhost and is set to a bare minimum. In production and test environments, set to 2–3 for better backup in a Kafka-clustered environment.
Partitions serve as a write-ahead log file, if you will. For each topic, Kafka keeps at least one partition, and that is the case in our example. However, in a production environment partitions are placed on a separate machine to allow for multiple consumers to read from a topic in parallel. Similarly, consumers can also be parallelized so that multiple consumers can read from multiple partitions in a topic, allowing for very high message-processing throughput.
Step-4. [optional] List the topics that are created.
bin/kafka-topics.sh — list — bootstrap-server localhost:9092

Topics List
So far we have started the Kafka Server with the topic named “item-sales” that Producers can publish to and Consumers can subscribe to. The topic is a message queue ready to take in the messages for the topic “item_sales.” Now we need to create a Cassandra sink table that Spark Consumer can write to.
The example used in this article is written in Scala as the Spark Consumer. The Spark Consumer is subscribing the input data that is fed as JSON from this topic and processed for further sinking to Cassandra tables. Use the example shown in my GitHub as a resource to understand the flow.
Step-5. Create the Cassandra Table
Create the Cassandra table with the following command:
TablePlus is a good database tool for the Cassandra client.
For SQL, Create Table:
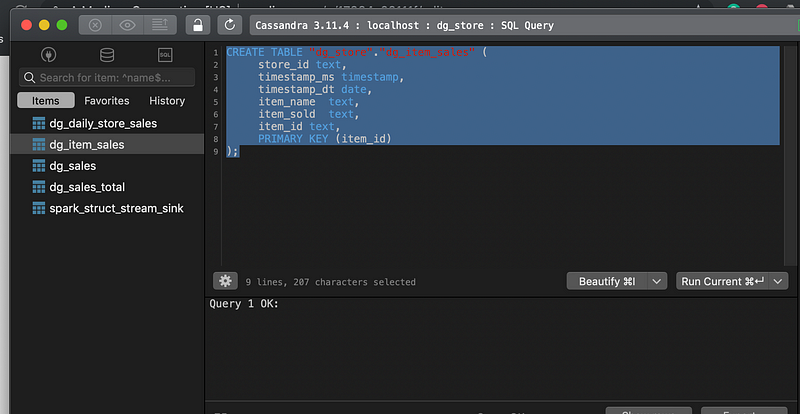
SQL Query to Create Table
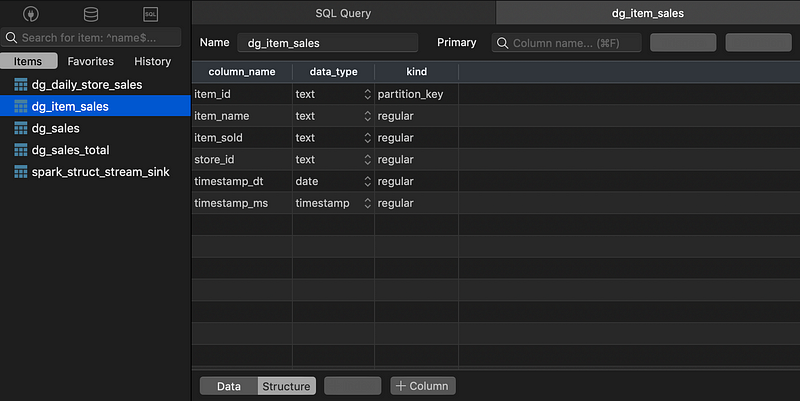
Table Structure of “dg_item_sales”
Step-6. Create the Scala consumer, refer here
The scala code that is reading the stream from the Kafka topic:
The JSON data set that this stream in expecting is as follows:
As streams are read from this data frame, similar to resultset or dataset, they can be used for transformation work. This is where the “transformation” of ETL takes place. Transformation can take place within the same code or can be delegated to different services or micro-services, or persisted directly to the database. These data stage rules are written and documented as per User stories and business requirements.
The custom schema can be defined and mapped to the incoming JSON:
As mentioned earlier, one of the biggest benefits of Spark is the abstraction of APIs, which makes integration with the systems very easy. The uniform data access provided by Dataframe SQL API supports a common way to access a variety of data sources, like Hive, Avro, Parquet, ORC, JSON, and JDBC.
For example, the JSON data input can be parsed and transformed from “timestamp_ms” to convert as “timestamp_dt” with both the fields saved to the database:
The parsed variable can be passed on for saving to Cassandra tables:
With the spark Consumer written we can start the Spark Consumer program from the IDE like IntelliJ. The Scala Consumer is listening to the topic and ready to process the JSON data as it comes.
Step-7. Feed the JSON message to the topic “item_sales”
bin/kafka-console-producer.sh — broker-list localhost:9092 — topic item_sales

With the Spark Consumer running from the IDE or the terminal, the JSON data is processed and saved to the Cassandra.
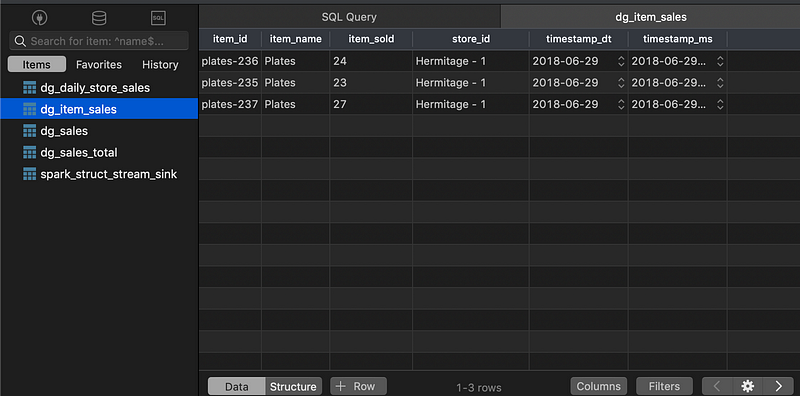
Data View after Spark Consumer Process
There are use cases where the transformed dataset can be further published to another topic in Kafka and thus become the Producer of the message from the Kafka point of view. This data pipeline processing and transformation decouples the system, making the architecture highly useful for Big Data processing.
Questions that might pop up while reading this or implementing this approach:
Why not use Only Kafka with Kafka Streams?: Kafka Streams are a recent addition compared to Apache Spark. Spark provides a much richer and more robust feature set that becomes useful in the long run for the organization, for example, like adding Machine learning models.
Why Cassandra and not RDBMS (MySQL, Oracle) or No-SQL Mongodb?
Cassandra is highly effective for write scalability scenarios, so with its clustered environment setup, it works extremely well with time-series data like IoT sensor data, social media data or any big data scenario.
Kafka allows for moving data between systems in an efficient and fault-tolerant manner. Apache Spark provides for processing data and acting on the data for transformation. Cassandra fits in for speed-writing of data as a persistent layer. This tech stack has proven to be successful for many companies, and I hope it helps you as well.
Resource:
https://github.com/objectstream/kafka-spark-cassandra-example
*Assumes you have installed the following: Kafka is installed from: https://kafka.apache.org/quickstart Spark is…*github.com